
A Scalable, Orchestrator-Agnostic Data Ingestion Framework Built on Spark & Scala
Introduction
Data ingestion is often the most underestimated layer in modern data platforms. While organizations invest heavily in analytics, AI, and dashboards, they frequently rely on fragmented, hardcoded ingestion pipelines that are difficult to scale, maintain, and standardize.
At Datilis, we address this challenge with Ingestion as a Service (IaaS)—a Spark & Scala-based ingestion framework designed to be reusable, configurable, and fully decoupled from orchestration tools.
This approach transforms ingestion from a collection of pipelines into a standardized, scalable platform capability.
The Problem: Fragmented and Rigid Ingestion Pipelines
Most organizations face common ingestion challenges:
- Pipelines tightly coupled to specific orchestrators
- Hardcoded logic for each data source
- Limited reusability across teams
- Difficult environment management (dev, test, prod)
- No built-in data quality validation during ingestion
- Scaling challenges as data volume grows
The result is:
- Increased development effort
- Inconsistent ingestion patterns
- Higher operational risk
- Slower onboarding of new data sources
The Datilis Approach: Ingestion as a Service
Our framework introduces a modular ingestion architecture built around three core principles:
1. Configuration-Driven Ingestion
Instead of writing pipelines per dataset, ingestion is defined using YAML-based configuration:
- Source type (JDBC, Kafka, SFTP, etc.)
- Target system (e.g., BigQuery, Hive)
- Load strategy (full, partitioned, incremental)
- Execution mode (cluster or local)
- Data quality checks
This enables:
- Rapid onboarding of new datasets
- Consistent ingestion patterns
- Reduced development effort
2. Decoupled Execution Layer (Spark & Scala)
At the core of the framework is a Spark-based ingestion engine implemented in Scala:
- Handles large-scale distributed ingestion
- Supports multiple ingestion patterns
- Optimized for performance and scalability
- Reusable across all ingestion use cases
Most importantly:
The ingestion engine is completely independent of orchestration tools.
It can be triggered by:
- Dagster
- Airflow
- Oozie
- Any scheduler or event-driven system
3. Orchestrator Integration (Flexible & Pluggable)
Using a Dagster-asset-factory/Airlfow-asset-centric approach, ingestion jobs are dynamically created from configuration:
- YAML → Airflow/Dagster assets
- Automatic context preparation
- Standardized execution patterns
This allows:
- Native integration with orchestration tools
- Consistent pipeline definitions
- Simplified scheduling and dependency management
Architecture Overview
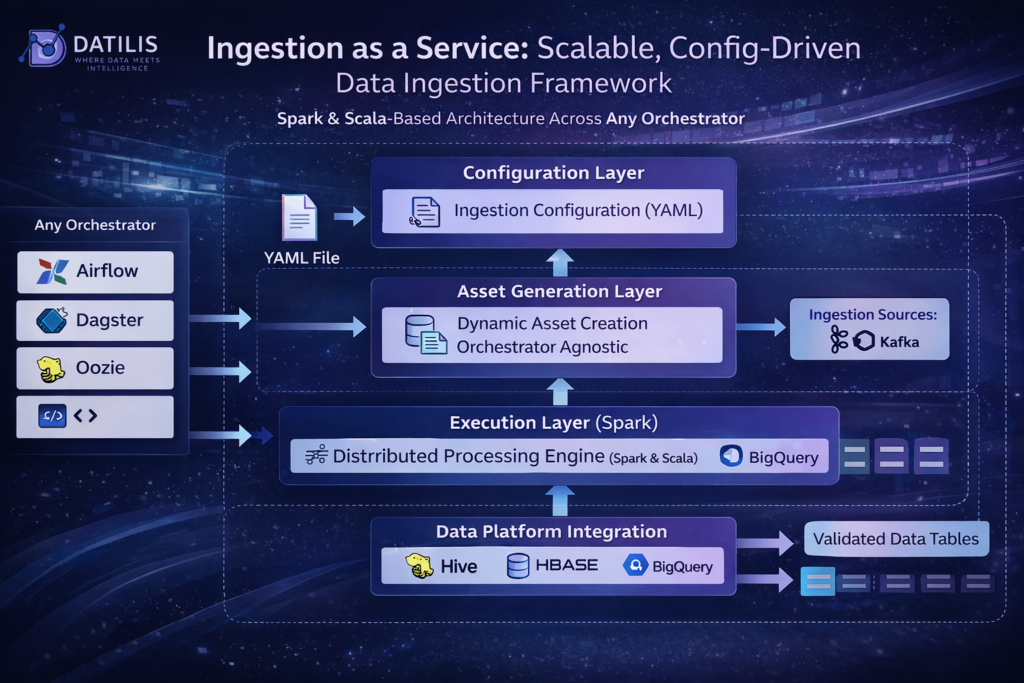
The ingestion framework operates as a layered pipeline:
Step 1: Configuration Layer
- YAML files define ingestion behavior
- Supports environment separation (dev, test, prod)
- Enables CI/CD-driven deployment
Step 2: Asset Generation Layer
- Airflow/Dagster asset factory creates ingestion jobs
- Translates configuration into executable pipelines
Step 3: Execution Layer (Spark)
- Distributed ingestion processing
- Handles large-scale data movement
- Supports multiple load strategies
Step 4: Data Platform Integration
- Data lands in target systems (e.g., BigQuery, Hive)
- Immediately available for transformation (dbt)
Step 5: Transformation & Validation
- dbt transformations applied
- Data quality checks executed during and after ingestion
Key Capabilities
Multi-Source Ingestion
Supports:
- JDBC databases
- Kafka streams
- SFTP/file-based ingestion
Flexible Load Strategies
- Full load
- Partition-based ingestion
- Incremental ingestion
Built-In Data Quality Checks
Data validation is executed during ingestion, ensuring:
- Early detection of issues
- Reduced downstream failures
- Higher data reliability
Reusable Framework Components
- Shared ingestion logic
- Centralized utilities
- Standardized processing patterns
Environment Isolation
- Separate dev, test, and production environments
- Safe deployment and testing
- CI/CD integration
Integration with Data Platforms
The framework integrates seamlessly into modern data platforms:
- Data is ingested into staging layers
- dbt transformations build downstream models
- Data becomes immediately usable for analytics and AI
This creates a continuous flow from ingestion to insight.
Business Benefits
Organizations adopting Ingestion as a Service achieve:
- 70–80% reduction in ingestion development effort
- Faster onboarding of new data sources
- Consistent and standardized ingestion patterns
- Improved data quality from the start
- Reduced operational complexity
- Scalability across growing data volumes
Strategic Value
Ingestion is not just a technical step—it is the foundation of your data platform.
By productizing ingestion, organizations gain:
- A reusable ingestion capability
- Faster time-to-data
- Improved governance and control
- A strong foundation for analytics and AI
Why Datilis
Datilis brings together:
- Deep expertise in data engineering and distributed systems
- Proven frameworks built on Spark, Scala, dbt, and modern orchestration tools
- A strong focus on standardization and reusability
- A commitment to delivering business value, not just pipelines
Conclusion
Ingestion as a Service transforms ingestion from a bottleneck into a scalable, reusable platform capability.
By combining:
- Configuration-driven design
- Distributed Spark execution
- Orchestrator flexibility
- Built-in data quality
Datilis enables organizations to build robust, future-proof data platforms.
Next Steps
- Identify key ingestion bottlenecks
- Standardize ingestion patterns across teams
- Launch a pilot with 1–2 data sources
Contact Datilis to implement your ingestion framework