Building Scalable, Auditable, and Flexible Data Platforms
As data platforms grow in complexity, organizations face increasing challenges in managing data consistency, scalability, and historical tracking. Traditional modeling approaches often fail to keep up with evolving business requirements and high data volumes.
At Datilis, we address this with Data Vault 2.0—a modern data modeling methodology that enables:
- Scalability across large data volumes
- Full auditability and historical tracking
- Flexibility to adapt to changing business needs
Combined with our frameworks for ingestion, data quality, retention, and data contracts, Data Vault becomes the foundation of a truly enterprise-ready data platform.
Why Data Vault 2.0
Data Vault 2.0 is designed for modern data platforms where:
- Data sources are diverse and constantly evolving
- Business requirements change frequently
- Historical tracking is mandatory
- Scalability and automation are critical
Key Advantages
- Scalability → Handles large and growing datasets
- Auditability → Full history of all changes
- Flexibility → Easy to extend without breaking models
- Parallelization → Enables distributed processing
- Automation-ready → Works seamlessly with modern pipelines
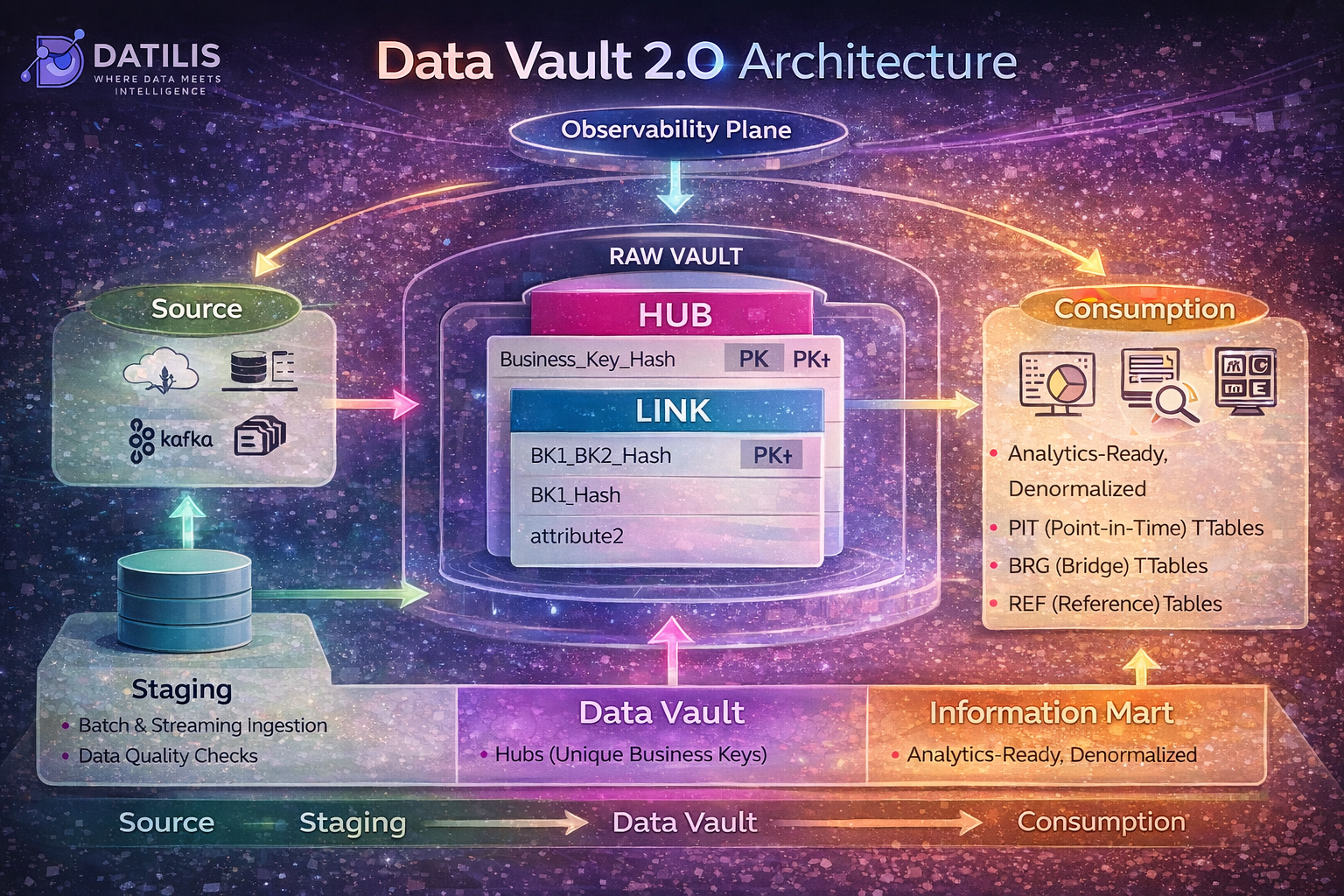
Core Components of Data Vault
Data Vault is built on three main entities:
🔹 Hubs — Business Keys
Hubs store unique business identifiers:
- Business Key (e.g., Customer ID)
- Hash Key (primary key)
- Load Date
- Record Source
Purpose:
- Centralize core business entities
- Ensure uniqueness and traceability
🔹 Links — Relationships
Links define relationships between business entities:
- Connect hubs together
- Store relationship keys
- Track associations over time
Purpose:
- Represent relationships (e.g., Customer ↔ Product)
- Enable flexible data modeling
🔹 Satellites — Descriptive Data
Satellites store descriptive attributes:
- Historical changes
- Contextual attributes
- Hashdiff for change detection
Purpose:
- Track data history
- Store evolving attributes
Architecture Overview

The Data Vault model fits naturally into your platform:
Flow:
Source → Staging → Raw Vault → Business Vault → Information Mart → Consumption
1. Source Layer
- Operational systems (databases, Kafka, APIs)
2. Staging Layer
- Raw ingestion (via Datilis ingestion framework)
- Minimal transformation
- Data quality checks applied
3. Raw Vault
- Hubs, Links, Satellites
- Fully auditable, immutable data
4. Business Vault
- Business logic applied
- Derived entities and rules
5. Information Mart
- Optimized for analytics
- Denormalized models
6. Consumption Layer
- BI tools
- AI/ML models
- Reporting systems
Integration with Datilis Framework
Data Vault 2.0 is not standalone—it is integrated with:
✔ Ingestion as a Service
- Standardized ingestion into staging
- Scalable data loading
✔ Data Contracts
- Enforce schema and expectations
- Prevent bad data at source
✔ Data Quality Framework
- Validate data across layers
- Ensure trust in vault structures
✔ Data Retention Framework
- Manage lifecycle of historical data
- Ensure compliance
Business Benefits
Organizations implementing Data Vault 2.0 achieve:
- Full historical traceability
- Reduced model refactoring effort
- Faster onboarding of new data sources
- Improved data governance
- Scalable architecture for AI and analytics
When to Use Data Vault
Data Vault is ideal when:
- You have multiple heterogeneous data sources
- You need auditability and compliance
- Your business logic evolves frequently
- You want to scale your data platform
Considerations
While powerful, Data Vault requires:
- Proper design and governance
- Understanding of modeling patterns
- Transformation layer for analytics (Information Mart)
This is where Datilis adds value—with frameworks and best practices.
Conclusion
Data Vault 2.0 provides the structural backbone of a modern data platform.
Combined with Datilis solutions, it enables: A scalable, governed, and future-proof data ecosystem