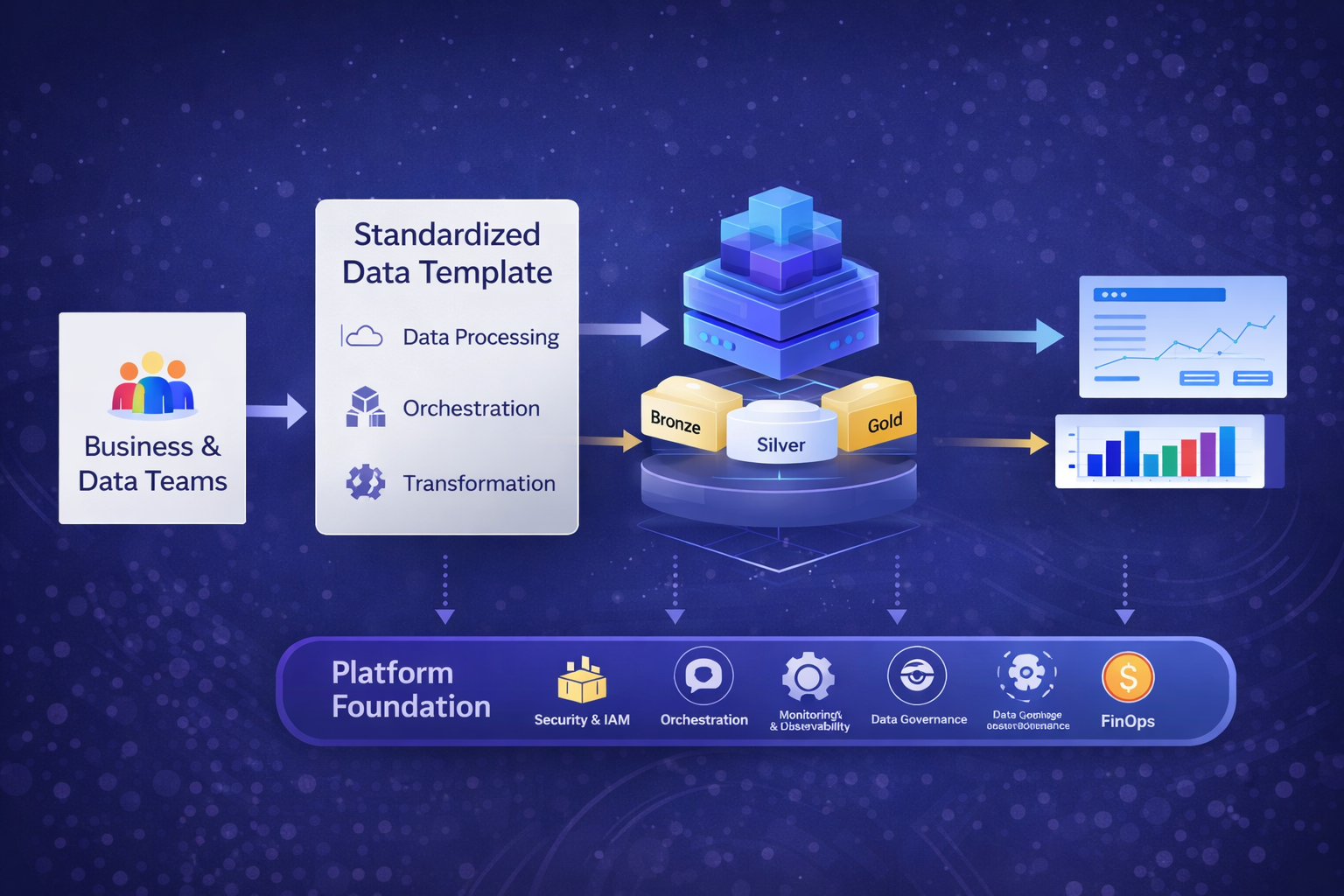
Building a data platform is no longer just about storing data. Organizations today need scalable, automated, and production-ready data engineering capabilities to support analytics and AI at scale.
At Datilis, we implement a modern data engineering stack that enables teams to move faster, standardize development, and operate reliably across environments.
This article outlines the key components of that stack and how they work together.
What Defines a Modern Data Engineering Stack?
A modern stack is not just a collection of tools, it is a cohesive system that enables:
- rapid development
- scalable processing
- automated orchestration
- governed data flows

Our approach is built around four key pillars:
1. Scalable Infrastructure
Modern data platforms require cloud-native infrastructure that can scale with data volume and use cases.
At Datilis, we focus on:
- cloud-based infrastructure
- reusable frameworks and components
- standardized deployment patterns
This allows teams to quickly onboard new use cases without reinventing the foundation.
2. Automated Orchestration
Manual pipelines do not scale.
We implement automated orchestration using tools like Dagster/Airflow to:
- manage dependencies between pipelines
- schedule workflows
- monitor execution
- ensure reliability
This enables dynamic and resilient data pipelines across environments.
3. Data Ingestion & Processing
Efficient data processing is at the core of any data platform.
We leverage modern tools such as:
- dbt for transformation
- Spark for large-scale processing, and
- containerized environments for portability
This allows us to:
- standardize transformations
- ensure reproducibility
- scale processing efficiently
4. Metadata & Governance
Without governance, data platforms become unreliable.
We implement:
- standardized metadata models
- data lineage and tracking
- governance tooling for compliance
This ensures that data is:
- trusted
- auditable
- usable across teams
Standardization Through Template Projects
One of the key accelerators in our approach is the use of template projects.
These templates include:
- preconfigured pipelines
- standardized tooling
- best practices for development
Teams can:
- customize templates for their use case
- reduce setup time
- ensure consistency across domains
Supporting Different Business Domains
The stack is designed to support different organizational needs:
- B2B use cases
- B2C use cases
- cross-functional data squads/teams
Each team can adapt the same foundation while maintaining consistency.
From Ingestion to Insights
The stack enables a full data lifecycle:
- Data ingestion
- Data processing
- Data transformation
- Business intelligence and analytics
All orchestrated through a unified platform.
Why This Approach Works
This modern data engineering stack provides:
- Scalability → supports growing data needs
- Speed → faster development and deployment
- Consistency → standardized workflows
- Reliability → automated orchestration and monitoring
- Governance → built-in control and compliance
How Datilis Delivers
At Datilis, we combine:
- data engineering expertise
- platform architecture
- DevOps and DataOps practices
to deliver production-ready data platforms, not just prototypes.
Conclusion
A modern data engineering stack is essential for organizations that want to scale analytics and AI.
By combining:
- scalable infrastructure
- automated orchestration
- standardized processing
- governance
organizations can build platforms that are robust, flexible, and future-ready.
Call to Action
Want to modernize your data engineering stack?
Let’s talk.